Javascript is an wonderful dynamic language; it allows us to do many things either on the backend layer with Node or the frontend of our application. One of the things that we do the most in javascript is endpoint calls that are later used to compute information and finally show it to the user in a friendly and polished way. We usually try to avoid at all cost additional requests and computations so that our application performs at its best. On this article, we're going to be exploring a technique that will help us improve on this matter, so without further ado let's get into it.
The premise
The idea is to take advantage of the browser's memory to store data that usually requires heavy computations to obtain it, and that's likely to be reused in the future, in this way we have the information ready to be accessed, and we don't have to re-run tasks to get it, this technique is known as memoization.
Understanding the dynamic behind it
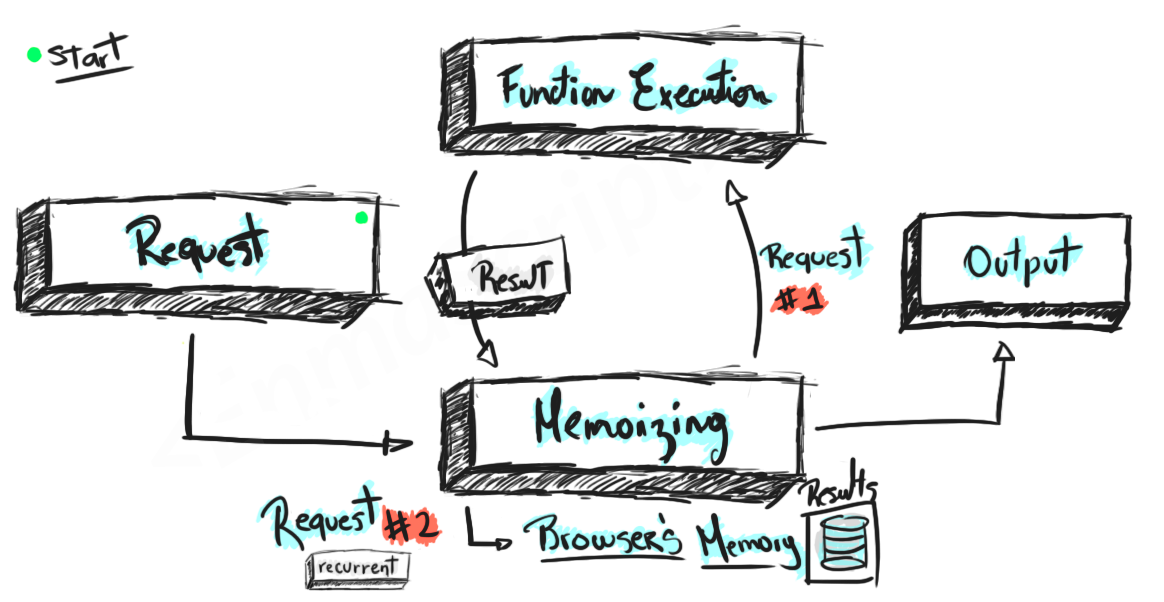
The image below explains the basic flow behind memoization to understand better how it fits in our application:
Let's analyze this image:
We're trying to call a memoized function with arguments A and B. Before executing it the memoization layer checks if it was called in the past with the same arguments, but, since it's not the case, it passes the information over and executes it on the first request (Request #1). The function then makes the computations and returns the result to the memoization layer where it's stored for later use. Now, the next time we try to run the function with the same parameters, the memoization layer will check if the arguments are recurrent, and, since they'll be we'll get the information from memory (Request #2) and then return it to us directly.
When to apply
It's recommended that we employ this technique when our function meets the following requirements:
Performs heavy tasks, therefore storing the result might help us save some processing time in our application.
Consistently receives the same arguments, so that we can avoid re-computing repeated data.
What is required to memoize our functions?
Ideally, to memoize a function it should follow the principles of purity, meaning that it should not contain side effects, it should explicitly depend on its arguments and return the same output for the same arguments passed. In this way, we can guarantee a successful memoization layer that's automatic and argument-dependent; this is pivotal for the technique to work consistently.
A use case
As mentioned at the beginning, one good use case for memoization is to avoid making extra network requests when the data we need has been already fetched and the computations to clean and show these data were already executed.
If you have what we call a "robust" architecture, you probably have a caching layer in the backend like Redis to avoid receiving consecutive hits on the database every time a user asks for recurrent information. If we apply this technique to the function that executes the GET request, we can even avoid making the endpoint call meaning that the network won't get agglomerated with tasks. Let's see how we can interpret this:
Now, this being said, memoization is something you'll apply in your applications as you notice that your functions meet the requirements.
Implementing a simple memoizer
Ok, it's been enough drawing and theory, let's create our own custom memoizer.
For what we've learned we know that the memoizer should receive a function as argument, then, we need to store the results in some data structure to be able to retrieve them later based on the function and arguments passed, let's see:
/**
* Receives a function which would be memoized
*/functionmemoize(fn){/* we'll use this object to store the results */let cache ={};/**
* Returns a function that will receive the arguments
* that will be passed to the memoized function (fn).
*/return(...args)=>{/* We stringify the arguments in case they're non-primitive values */const cacheKey =JSON.stringify(args);/* were the arguments already passed? if no, then store the result */if(!(cacheKey in cache)){
cache[cacheKey]=fn(...args);}/* We then return the stored result */return cache[cacheKey];};}
And then we would use it like this:
/* A simple add function that will be memoized */functionadd(a,b){
console.log('Executing the sum');return a + b;}/* we pass the function definition to the memoizer */const memoizedAdd =memoize(add);/* we now run the memoized add function */memoizedAdd(1,2);// logs "Executing the sum" and returns 3memoizedAdd(1,2)// doesn't log anything, returns 3 directly.
In the implementation of the memoize function persistency works thanks to closures, The cache object is stored in memory thanks to the variable memoizedAdd, then, thanks to that variable we're able to execute the returned function and get the results as needed. If you have issues trying to understand this concept, I recommend you to read the article about Higher Order Functions.
A better implementation
If you analyze the previous implementation a little bit you will realize that we have to worry about a couple of things:
Memory consumption, if the results and keys we're storing are large sets of data and we store them multiple times this could cause memory issues in the future, this won't happen often but it's important to keep it in mind.
Knowing this, here a more complete implementation that will allow you to clear the cached elements.
With this we're able to clear the cache manually when we need it, and example of usage:
const memoizedAdd =memoize(add);
memoizedAdd.process(1,2);// Executes the function
memoizedAdd.process(1,2);// Hits the cache
memoizedAdd.get();// returns the object with the memoized elements
memoizedAdd.count();// returns the number of elements stored so far
memoizedAdd.clear();// clears the cache
And just like that we have a more complete implementation. Also, thanks to the count and clear method we can clear the cache when we consider it relevant.
It's worth mentioning that this technique is widely used, if you have used selectors in redux in the past you'll find out that Reselect applies memoization; also libraries like lodash have their own implementation...
Important to know: you don't explicitly need a function called memoize or an isolated function for that matter to apply this technique, as long as your implementation respects the principle behind memoization, you can implement it in a custom way based on the functions you're working on, the examples on this article are just a reusable way to apply this principle.
Ok, guys, I think that's it for now, I hope you've enjoyed the article... If it was the case remember to share it with your friends and coworkers. If any questions remember you can catch me in twitter at @duranenmanuel.
Big O notation allows us to evaluate the performance of algorithms so that we can determine their efficiency and make decisions based on this determinations, let's try to understand how this notation works and how we can apply it in our lives as software developers.Read more
Linked Lists are a fundamental data structure in the world of software development, in this article we will explore its implementation and its applications in today's worldRead more